
W poprzednim artykule pisałem o Spring Webflux. W tym artykule przedstawię krótki przykład jak Webflux działa. I jak uruchomić projekt bazujący na tym module Springa.
Webflux jest rozszerzeniem do budowania aplikacji reaktywnych. Z jego użyciem można to zrobić w bardzo podobny sposób, tak jak robimy to w klasycznej aplikacji Spring Mvc. Moduł ten pozwala używać tych samych mechanizmów springowych, m.in.: adnotacji @RestController, czy mappingów np. @GetMapping
Stworzę bardzo prostą aplikację testową, która wystawia REST API, więc z zewnątrz nie będzie różnić się od aplikacji opartej na zwykłym Springu Mvc.
Zacznijmy od wygenerowania sobie projektu Spring Boot (przy pomocy spring initializer
Poniżej wygenerowane zależności gradlowe:
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-webflux'
implementation 'org.springframework.boot:spring-boot-starter-data-mongodb-reactive'
// ...
}Po wygenerowaniu projektu należy go zaimportować w IntelliJ (jeśli generowałeś go na stronie).
Tworzymy kod aplikacji
Teraz możemy przystąpić do napisania pierwszego kontrolera i wystawienia pierwszej usługi. Powiedzmy, że nasz kontroler będzie odpowiedzialny za wystawienie listy książek BookController. Podobnie jak w zwykłym Springu, oznaczamy go adnotacją @RestController, a metodę, która wystawi nam usługę oznaczmy adnotacją @GetMapping. Jako parametr value podajemy "/books" – do tej pory wszystko jest tak samo, jak w klasycznym springu. Metoda getBooks() wywołuje metodę z repozytorium BookRepository, które jest reaktywnym repozytorium MongoDB.
package net.mdabrowski.springwebflux.controller;
import net.mdabrowski.springwebflux.model.Book;
import net.mdabrowski.springwebflux.repository.BookRepository;
import org.springframework.http.MediaType;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import reactor.core.publisher.Flux;
import java.time.Duration;
@RestController
public class BookController {
private final BookRepository bookRepository;
public BookController(BookRepository bookRepository) {
this.bookRepository = bookRepository;
}
@GetMapping(value = "/books", produces = MediaType.APPLICATION_STREAM_JSON_VALUE)
public Flux<Book> getBooks() {
return bookRepository.findAll()
.delayElements(Duration.ofSeconds(5));
}
}I teraz pojawiają się różnice: metoda getBooks() zwraca Flux<Book> jeden z dwóch typów reaktywnych dostępnych w Spring Webflux (o typach Flux i Mono pisałem więcej w poprzednim artykule). Dla przypomnienia Flux jest publisherem, który zwraca wieloelementowy strumień, więc zamiast listy książek dostajemy strumień książek. Na razie jeszcze nie do końca widać co to oznacza, ale jeśli dodamy do tego MediaType w parametrze produces adnotacji @GetMapping i ustawimy go na APPLICATION_STREAM_JSON_VALUE, to już zobaczymy znaczącą różnicę. W tym momencie, dzięki tym dwóm rzeczom, nasza aplikacja powinna zwracać strumień elementów, gdzie każdy z osobna będzie z serializowany do jsona (zamiast z serializowanej listy obiektów w jsonie). Powinno wyglądać to tak, jak na poniższym obrazku:
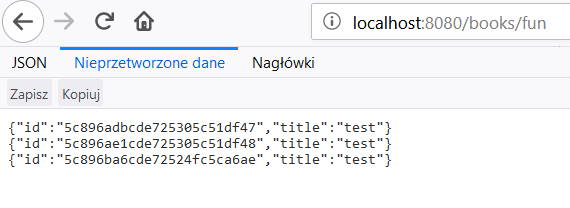
Nasza aplikacja kliencka musi być przystosowana do tego, że otrzymuje strumień jsonów a nie jednego wielkiego json’a.
Żeby lepiej zobrazować i za symulować opóźnione pojawiania się poszczególnych elementów strumienia, użyłem metody Fluxa
.delayElements(Duration.ofSeconds(5)), która opóźnia poszczególne elementy (w tym wypadku o 5 sek.)
W repozytorium MongoDb używamy klasy ReactiveCrudRepository z pakietu org.springframework.data.repository.reactive.
package net.mdabrowski.springwebflux.repository;
import net.mdabrowski.springwebflux.model.Book;
import org.springframework.data.repository.reactive.ReactiveCrudRepository;
import org.springframework.stereotype.Repository;
@Repository
public interface BookRepository extends ReactiveCrudRepository<Book, String> {
}
Klasa Book musi być oznaczona adnotacją @Document
package net.mdabrowski.springwebflux.model;
import org.springframework.data.mongodb.core.mapping.Document;
import java.util.Objects;
@Document
public class Book {
private String id;
private String title;
// .. getters, setters, constructors ...
@Override
public String toString() {
return "Book{" +
"id='" + id + '\'' +
", title='" + title + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Book book = (Book) o;
return Objects.equals(title, book.title);
}
@Override
public int hashCode() {
return Objects.hash(title);
}
}
Strumienie reaktywne
Każdy z elementów strumienia może, zostać zwrócony w różnym czasie. Elementy strumienia będą zwracane dopóki strumień nie zostanie zamknięty. W normalnej komunikacji synchronicznej, serwer zwraca całą odpowiedź w „jednym momencie”. Tutaj dane mogą być po porcjowane.
Prezentuje to poniższy schemat:

Możesz testowo usunąć mediaType produces = MediaType.APPLICATION_STREAM_JSON_VALUE z adnotacji @GetMapping. Zobaczysz wtedy różnicę w sposobie zwracania odpowiedzi przez serwer. Z racji tego, że każdy element strumienia jest opóźniony o 5 sek. serwer będzie czekał, aż zgromadzi wszystkie elementy i strumień zostanie zamknięty. Dopiero wtedy odpowiedź zostanie zwrócona do klienta, więc komunikacja pomiędzy klientem i serwerem będzie synchroniczna. Dodatkowa różnica jest taka, że usługa zwróci wtedy z serializowaną listę json.
Testy integracyjne z WebTestClient
Webfluxa możemy testować przy pomocy klasy WebTestClient. Klienta można skonfigurować automatycznie przez adnotację @AutoConfigureWebTestClient. Ja dodatkowo ustawiłem timeout klienta na 20 sek. ze względu na to, że używam do opóźnienia elementów metody .delayElements(...). Poza tym nie ma większych różnic w testowaniu webfluxa i tradycyjnej aplikacji springowej.
package net.mdabrowski.springwebflux.controller;
import net.mdabrowski.springwebflux.model.Book;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.autoconfigure.web.reactive.AutoConfigureWebTestClient;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import org.springframework.test.web.reactive.server.WebTestClient;
import java.time.Duration;
import java.util.Arrays;
@RunWith(SpringRunner.class)
@SpringBootTest
@AutoConfigureWebTestClient
public class BookControllerTest {
@Autowired
WebTestClient webTestClient;
@Before
public void setUp() throws Exception {
webTestClient = webTestClient
.mutate()
.responseTimeout(Duration.ofSeconds(20))
.build();
}
@Test
public void messageWhenNotAuthenticated() throws Exception {
this.webTestClient
.get()
.uri("/books")
.exchange()
.expectStatus().isOk()
.expectBodyList(Book.class)
.isEqualTo(Arrays.asList(
new Book("test"),
new Book("test"),
new Book("test")));
}
}
Usługi wystawiane w sposób funkcyjny
Poza tradycyjnymi adnotacjami, nowy moduł webflux oferuje także wystawianie usług w sposób funkcyjny. W zasadzie, nie różni się to znacząco od tradycyjnego podejścia opartego na adnotacjach. Tylko zamiast adnotacji „rejestrujemy” tak jakby metodę (Handler Function), która będzie wystawiała naszą usługę. I używamy do tego specjalnej funkcji (Route Function).
W spring frameworku w wersji 5 pojawiła się także możliwość tworzenia beanów w sposób funkcyjny.
Poniżej przykład handlera, który będzie obsługiwał naszą usługę.
package net.mdabrowski.springwebflux.controller;
import net.mdabrowski.springwebflux.model.Book;
import net.mdabrowski.springwebflux.repository.BookRepository;
import org.springframework.http.MediaType;
import org.springframework.stereotype.Component;
import org.springframework.web.reactive.function.server.ServerRequest;
import org.springframework.web.reactive.function.server.ServerResponse;
import reactor.core.publisher.Mono;
import java.time.Duration;
@Component
public class BookHandler {
private final BookRepository bookRepository;
public BookHandler(BookRepository bookRepository) {
this.bookRepository = bookRepository;
}
public Mono<ServerResponse> getBooks(ServerRequest request) {
return ServerResponse.ok()
.contentType(MediaType.APPLICATION_STREAM_JSON)
.body(bookRepository.findAll().delayElements(Duration.ofSeconds(5)),
Book.class);
}
}
Gdy mamy już zdefiniowany handler, musimy go podpiąć pod odpowiedni URL. Służy do tego właśnie funkcja route(...) – jest ona klejem, który łączy nasz kod biznesowy w serwerem http. Umieszczona w klasie konfiguracyjnej wystawia naszą usługę na świat.
package net.mdabrowski.springwebflux;
import net.mdabrowski.springwebflux.controller.BookHandler;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.reactive.function.server.RouterFunction;
import org.springframework.web.reactive.function.server.RouterFunctions;
import org.springframework.web.reactive.function.server.ServerResponse;
import static org.springframework.web.reactive.function.server.RequestPredicates.GET;
@Configuration
public class BookConfiguration {
@Bean
public RouterFunction<ServerResponse> booksRoute(BookHandler bookHandler) {
return RouterFunctions.route(GET("/books/fun"), bookHandler::getBooks);
}
}
Funkcyjnie vs Adnotacje
Nie widzę, większej różnicy w obu podejściach. Podejście funkcyjne jest na pewno mniej intuicyjne dla wielu programistów piszących przez lata przy użyciu adnotacji. Na szczęście developerzy Springa nie każą nam jeszcze wybierać funkcyjnego podejścia. Moim zdaniem, ciężko będzie przyzwyczaić developerów do podejścia w pełni funkcyjnego. O ile elementy funkcyjne w Javie są bardzo przydatne, to w pełni funkcyjne programowanie w Javie i używanie elementów funkcyjnych wszędzie tam, gdzie to tylko możliwe raczej się nie przyjmie.
WebClient – reaktywny klient http
Nowy moduł daje nam także nowego reaktywnego klienta http, dzięki któremu możemy wywoływać zewnętrzne usługi.
package net.mdabrowski.springwebflux;
import net.mdabrowski.springwebflux.model.Book;
import org.springframework.web.reactive.function.client.WebClient;
public class WebClientApp {
public static void main(String[] args) {
WebClient.create("http://localhost:8080")
.get()
.uri("/books")
.retrieve()
.bodyToFlux(Book.class)
.doOnNext(x -> System.out.println("#: " + x))
.blockLast();
}
}
Klient jest nieblokujący, co sprawia, że musiałem użyć metody .blockLast(), żeby zablokować główny wątek aplikacji, aż zostanie zwrócony ostatni element. W innym wypadku nasz aplikacja zakończyłaby się zanim zdążyłaby otrzymać wynik z wywołania usługi http://localhost:8080/books. Natomiast w normalnej aplikacji reaktywnej zamiast metody .blockLast() użyłbym metody .subscribe().
Podsumowanie
Na pierwszy rzut oka budowanie aplikacji reaktywnych wydaje się bardzo proste. Wystarczy użyć odpowiedniego modułu Springa, zapoznać się z dwoma reaktywnymi typami danych Mono oraz Flux i właściwie to wszystko.
Niestety nie jest tak prosto. Musimy pamiętać przede wszystkim o jednej bardzo istotnej rzeczy. Nie możemy blokować wątków aplikacji, czyli wszystkie czasochłonne operacje muszą być obsłużone w sposób nieblokujący.
Problemy pojawiają się wtedy, kiedy programista nie do końca zdaje sobie sprawę co jest blokujące, a co nie. Używając MongoDb mam pewność, że pobieranie danych z tej bazy jest bezpieczne, ponieważ client MongoDb wspiera taką komunikację. Natomiast praca z sql’owymi bazami danych nie jest możliwa ze względu na blokujące JDBC. Także większość różnego rodzaju bibliotek, które odczytują lub komunikują się z różnymi źródłami danych działa w sposób synchroniczny i zawsze będą blokowały wątki naszej aplikacji. Po naszej stronie stoi obsługa tych wszystkich sytuacji. Są na to wprawdzie różne sposoby, ale zwykle wiążą się one z wieloma problemami.
Przykład zamieściłem na githubie: springwebflux
PS. Artykuł został przeniesiony z mojego starego bloga, którego już dawno nie rozwijam. W ten sposób chciałem ocalić go od zapomnienia 😉






Przydatny tekst, dzięki 🙂